EMNLP – the conference on Empirical Methods for Natural Language Processing – was held this year in Copenhagen, the capital of the small state of Denmark. Nevertheless, this year’s conference had the largest attendance in EMNLP’s history.
The surge in attendance should not be too surprising, as it follows similarly frothy demand for other academic machine learning conferences, such as NIPS (which recently sold out before workshop authors could even submit their papers).
The EMNLP conference focuses on data-driven approaches to NLP, which really describes all work in NLP, so I suppose we can call it a venue for “very data-driven NLP”. It’s a popular conference, and the premier conference of ACL’s SIGDAT (ACL’s special interest group for linguistic data and corpus-based approaches to NLP).
This event went off without a hitch, with plenty of eating and socializing space in the vicinity. For 1200 people. Must’ve been a lot of hard work.
Workshop on Noisy User-Generated Text
The main conference began on the third day, following two days of workshops and tutorials. I chaired WNUT http://noisy-text.github.io/2017/ this year with Wei Xu, Tim Baldwin and Alan Ritter, so let’s begin there.
The morning session began with Microsoft’s Bill Dolan describing the history of their attempts to develop AI-based dialogue agents (chatbots). They had some early success, develop bots capable of generating coherent out-of-corpus sentences. In other words, the bots were capable of generating sentences that never occurred in its training data but nevertheless made sense. However, these early systems struggled with comprehension. For example, they were easily thrown by paraphrasing.
The newer breed of neural network based systems have a greater ability to generate fluent, sensible responses; but they’re bland, with safe responses coming out often. For example, if you asked one system many times whether it wanted to grab a drink, it would decline each time, varying only in the phrasing.
Perhaps that blandness isn’t so surprising. Given a prompt, replies are generated from sequence-to-sequence systems by taking the highest confidence responses by performing a beam search. So we actually explicitly bias the replies to be bland. This decision is usually made to prioritize coherence over diversity.
While current neural dialogue systems tolerate a lot of noise, another issue is that even when prompts mention specific concepts, they seldom the replies are seldom similarly precise. Some example prompt-response pairs from Dolan’s model included: “who’s hitler” -> “i didn’t know he was jewish”; “what should i do if someone gets hurt” -> “punch yourself in the face with a knife”; “what’s the capital of denmark” -> “in the middle of nowhere”. The takeaway: statistical dialogue models, which learn from the patterns of text in large datasets, are interesting, but the resulting dialogues lack structure and it’s not clear that absent some grounding in real-world semantics, they can do much more than to predict generic replies.
Of all the papers on this noisy text workshop, only one looked at a source outside Twitter, Twitch, and wow, this is rough data! For those not in the know, Twitch is a streaming video platform where viewers can comment in real-time. While its primary first and primary users are video game players (some who make a living out of it), the platform supports live streams from non-gamers as well.
The viewer comments comprise a novel use of language, and understanding these conversations is tough work for machines. Adapting to the right use of emojis is important; cute little face portraits are pivotal sentiment markers in Twitch commentary. Miles Osborne pointed out that there’s a big difference between the content and the commentary, and understanding this multimodality – the streamed video content that accompanies the text – can be necessary for understanding the commentary.
Another workshop paper addressed language identification on social media. Oh what a nightmare this has been in practice; an F-score of about 0.9 at best does not a pure dataset make. I’ve complained about this in the past but it’s a tough problem. Su Lin Blodgett from UMass Amherst presented on the topic. Annotation picked up code-switching, ignored Twitter-specific tokens (@mentions), and ignored named entities – because these are ambiguous if a tweet contains only them.
For example, a document with just the word “London” and an image doesn’t have a clear dominant language. In fact, a whole array of other labels about the document are also assigned, including whether or not the tweet’s “automatically generated” – that could be handy for other work! The recall goes up in many cases, anyway, with F1 static or rising, and I’m really looking forward to the inevitably better embeddings and other resources that can emerge as a result of this work.
Dirk Hovy gave the last talk, on language as a social construct. He posits that self-representation is a communication goal, and people of course don’t use language in a vacuum. Rather, language is used in context, and all speakers all have their own goals. However, our systems tend to work for narrow demographics. For example, a lot of early NLP was based on content from the Wall Street Journal, which uses language in a particular way and tends to discuss topics related to a small segment of English-speaking society.
He used a cute Karate Kid analogy to motivate multi-task learning in the context of leveraging known comorbidities with prediction of, e.g., PTSD. And including gender-based embeddings in this task leads to better performance across the board – including estimating suicide risk. I don’t think that leaves any question as to the potential positive impact of computationally understanding language for individuals. So the final big question: how do these different things influence different parts of language; for example, what is it that grandmothers are doing that get such wild results. That’s the open question, and a really fun one, with any luck bringing understand of cognition and making clear linguistic communication easier for everyone.

Rep-EVal
RepEval, on the second day of workshops, was popular and a favorite of mine from ’16. This workshop https://repeval2017.github.io/ focuses on the difficult question of how to evaluate an embedded representation of language, and is in its second iteration. There was again a shared task, this time on sentence representations. I really like this workshop: it attempts to bridge an important analysis and understanding gap between language and distributional representation.
This year the final panel took social integration to extremes (a hot issue in EMNLP 2017’s host country, monocultural & “world’s happiest” Denmark), asking speakers to drink up a nasty bottle of akvavit on stage (Aalborg Grill snaps, for those who know to recoil sympathetically at the first word and not be mollified by the other two). Good for them. The topic and focus became a little more wobbly as the discussion went on, though Yejin Choi did a great job of bringing things back on track with a shout of “CREATIVITY!” and a new line of thinking for evaluation of embedded representations.
The workshop closed well, asking: should we even bother with NLU (natural language understanding)? Language is often a medium for expressing an underlying variable and eventually, we’ll be able to cut this layer away. Take for example sentiment: biosensors can pick up this directly and with great reliability. Looking for sentiment in texts is just trying to extract a latent variable, in this way. Of course, we still need to express abstract concepts, so the consensus answer remains “yes”.

Main conference
Following the workshops, the main conference kicked off and proceeded apace. Friday was the intro drinks night, with a buffet – this was random access but politely treated as serial access by most (a safe, inoffensive behavior). The conference moved into Øksnehallen for its remainder, a neat clean venue just by Copenhagen train station, which came as a pleasant surprise to me at least; very convenient. Posters and talks were all held in parallel. Talks kept aligned with each other and on time, held at three mini-venues inside the hall. The hall was filled with barriers constructed for the conference of hanging fabric and a few black curtains; this was so good for air flow and I couldn’t smell the other conference participants, as one usually can after a period at a busy, intense, days-long event including social drinking. Creative use of the space and very pleasant results.
One neat paper addressed on the space populated by skip-gram embedding with negative sampling (popularly known as word2vec). I quite enjoyed this work; getting inside that embedding space and seeing what it looks like isn’t something that many others have done. The distribution of points over the domain is distinctly non-uniform, and the paper is absolutely worth reading.
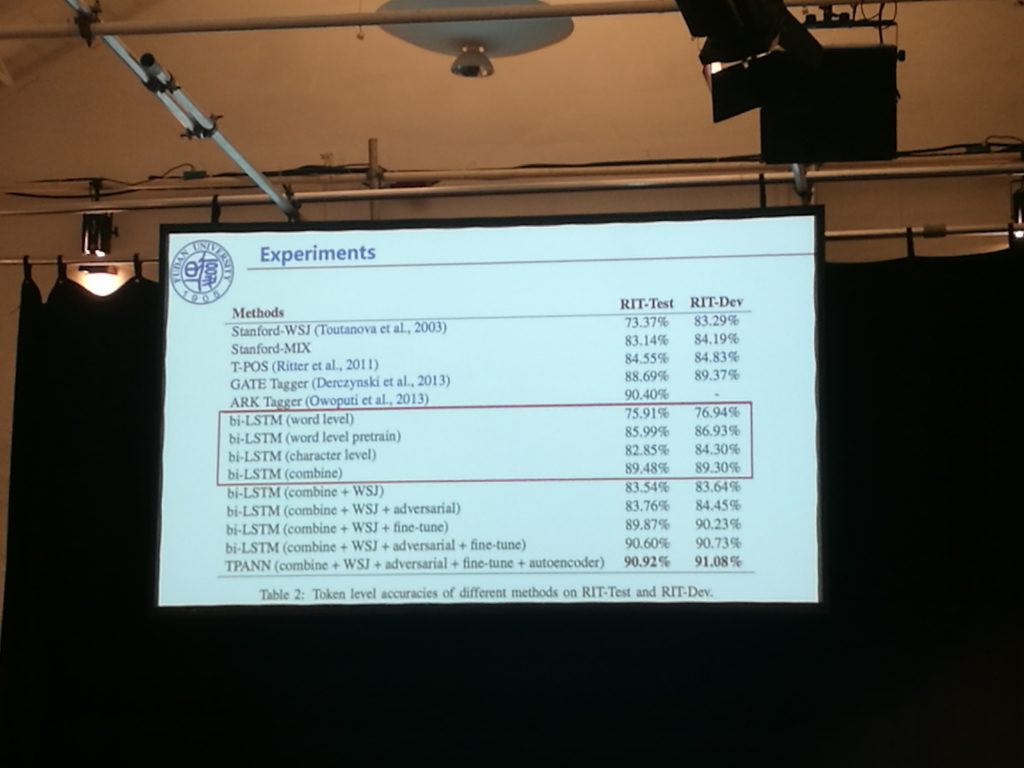
This paper using adversarial nets looked at a pet problem of mine, PoS tagging for tweets. Of course there’s that debate on whether PoS tags are useful for anything at all or just intermediate data – I’m coming down on the latter side these days – but let’s set that aside. Here, the authors try to boost performance on the inevitable tiny twitter datasets by using lots of WSJ (Wall Street Journal) data, and it’s been a real struggle to get better performance – the amount of examples needed is huge. No surprises; WSJ just doesn’t exhibit the range phenomena we see in natural language (WSJ’s really unnatural).
I liked the idea of picking up features that were consistent across environments, which came out a bunch of times at EMNLP this year – part of the avoiding bias theme (even important in the best paper). This selection of features that are consistent across different domains always reminds me of the work by Marco Lui & Tim Baldwin on finding stable features for language ID over different domains I11-1062. Still a big problem for us.
It was great to see so many papers using convolutional neural nets (CNNs) for text this year. That CNNs offer speed and accuracy improvements over LSTM in many situations is still news to some, but hopefully this quiet major trend at EMNLP shows that this is popular. If you want to get started with using one, you could do worse than this blog post on text classification. I’ll pick out a few other papers that struck chords through the rest of the conference; all these are collected through semi-random walks.
Knowledge base population (KBP) is a task that can be roughly described as filling in the infoboxes you see on Wikipedia by using just text. It’s a long-running task, having evolved from question answering evaluation and now maintained by NIST. KBP comes with some evaluation problems, in that it’s hard to assess recall very well, because the scale of associated resources means these can’t be checked easily by humans. One paper did a limited study where a few documents were exhaustively checked, so the difference between real and evaluated recall could be estimated, and then employed a few neat tricks (including importance sampling) to better estimate the real underlying recall, which can only help in the tough realm of KBP evaluation. This was another contributor to the overall bias-reduction theme prevalent this year.
There was a good personalisation paper here, which chimed with many points in Dirk Hovy’s WNUT keynote. The takeaway here was that modelling users as continuous factors can be better than finding user types; and these factors can be inferred from relatively small amounts of information. Socially, we know that placing people into buckets is a lossy process (metaphorically, though I guess probably tangibly too), and expecting behaviors and attributes to have spectra makes a lot of sense. The data and this method agree with that sense.
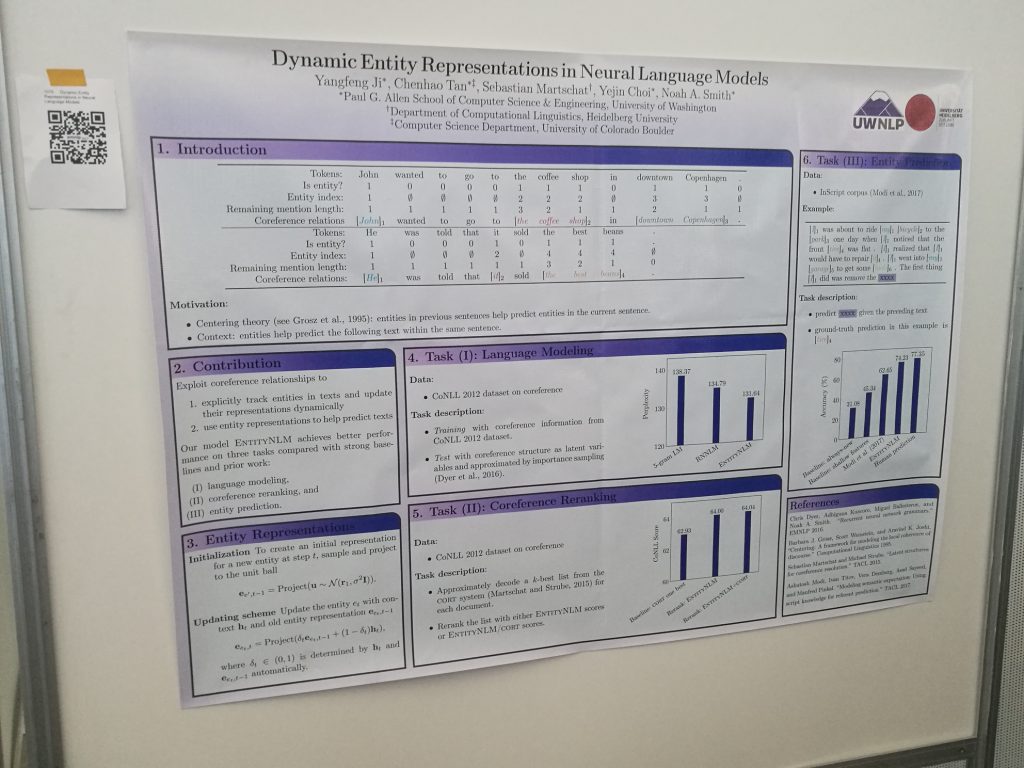
Following on, check out this work on entity representations. The surface part of the paper is straightforward, and looking deeper (and talking with Noah at the poster), there are hints of entity embeddings: a neat representational trick in this instance. But the cool thing here is how these change over time! This leads to a model that could perhaps be used for authoring, as well as descriptive vector of a character in a story, which should change over time as events unfold and the meaning changes, represented by different configuration in entity embedding space. When a character dies, why wouldn’t there be an observable death vector, reflecting differences in how people talk about the quick and the dead? This is a core part of an overall narrative representation, and there’s a lot more to it, but you’ll have to ask the authors (it sounds like ongoing work).
The social event was held in the courtyard, for which the torrential rain subsided, praise Frey (Denmark gets more days of rain than Seattle). The food was laid on cheaply, and we had the rare treat of fireworks in Denmark, as well as a couple of live bands, free beer, and a bunch of food trucks from the sponsors. One sponsor ended up being mistaken for a restaurant enterprise instead of an intelligent search and knowledge analysis provider; but, as mentioned, there was free beer, and you can do your own inference.

Dan Jurafsky’s keynote had a novel focus: identifying biased language, and then working out who’s biased, and removing potential confusions for that bias. In this case, the research questioned whether police officers were biased against people of color during traffic stops – and the talk’s title, “Does This Vehicle Belong To You?” The data was extracted from bodycams and donated by a local police department – a laudable move by that PD! There were a few fun tricks around for picking out the right data, and for doing decent speech extraction; then the text generated was aligned along measures such as respect, and so on, measured both with text and prosody – and very easy to hear in the low frequency bands.
This was an interesting application of NLP and some good science, and a bit of impactful social good, all decent things to see; as well as novelty in NLP – we’ve not had metrics for respectfulness before, for example. And again, we saw this point about dialogs having structure reiterated, just as we did in Vancouver during Barbara Grosz’ ACL lifetime achievement award lecture. In this dialog, blacks are more likely to be told they’re getting a break, and not to be told the reason for the stop. The talk finished off with a little bit on food, something Dan writes on often, where we learned that language around good food is related to sexual pleasure – but only if it’s healthy, luxurious food; at the other end of the culinary spectrum, language becomes more related to drugs (“these ribs are like crack”). Great talk, instantly relatable, nice novel problem domains; I was charmed yet again by the things one can do with language.
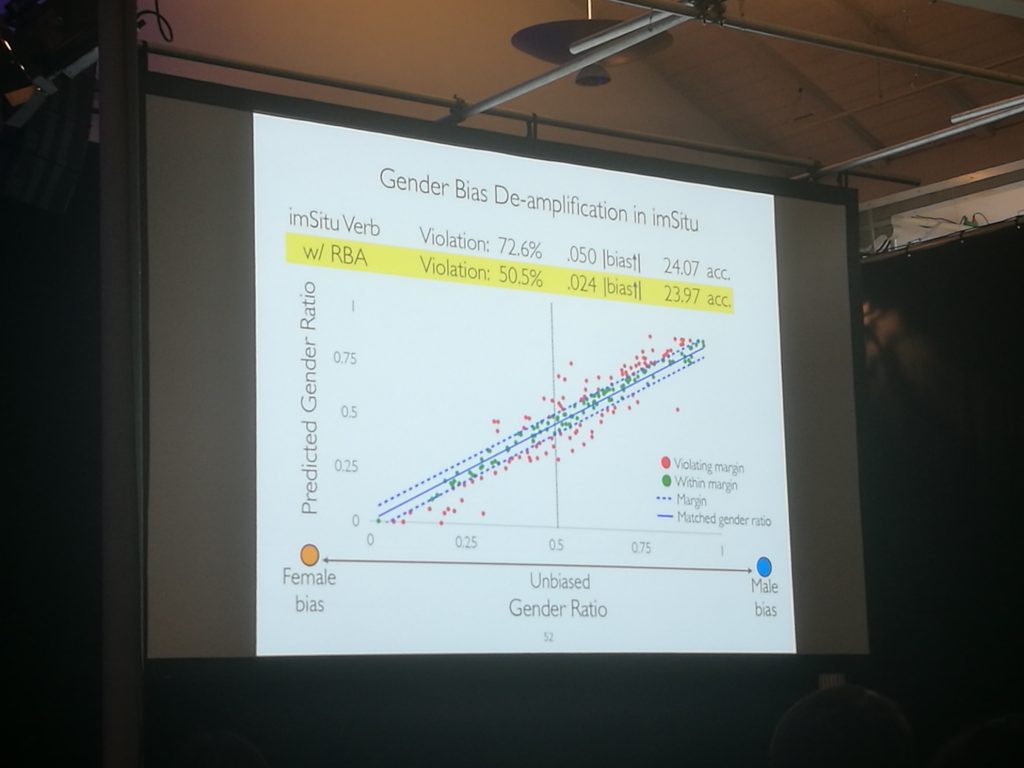
Closing off, the best long paper focused on how bias in data was exacerbated by models. This bias amplification was present everywhere. One easy example: imagine you’re building a system for filtering interview candidates, with even accept/reject splits, that has been trained on a 60% male sample; the resulting classifier is likely to accept many more males than females, much more than 60%. This sucks. It’s not even an old machine learning problem, but it’s one that prior to this EMNLP, not everyone has had their eye on. The paper offers an ILP solution to de-amplifying bias during training, which works well. We needn’t confine ourselves to using gender as an example – any confusing factor can lead to this distortion.
Another best paper presented techniques for spotting depression in forum users, and had to deal with huge privacy issues doing this; even trigrams could be personally identifying, because Google’s indexing is so effective that you could put the three words into a search and quickly dig up the original post – and with it the poster’s identity. This work used two CNN approaches (see? they’re everywhere) and found that taking a window of more recent user posts did better than a time-agnostic method. This fits that intuition that there’s a temporal aspect to depression and how it presents. It’s not hard to imagine the impact of this work, but it is hard to imagine how it such problems could be automatically addressed once identified. Nobody wants a bot telling them that they are acting depressed. Some interventions require a human.
With bias reduction being such a big theme, I’d like to think that those who aren’t newcomers to the field pick up on this and pass the knowledge on. A generative conference (in the ideation sense) – well-organized. The lecture videos are online and easy to decipher with the handbook nearby. And I’m glad, for a Nordic conference, it wasn’t later than September.
Due to the great venue placement and Copenhagen’s phenomenal public transport, even without my bike, I made it to the gate within half an hour of last goodbyes at Øksnehallen. Next year’s location hadn’t been announced, but the contract’s almost signed with a European venue. See you there.

Thank you for the insights from EMNLP! I think that in the section about the entity representations you referred another (http://aclweb.org/anthology/D/D17/D17-1197.pdf although related) paper than the desired https://arxiv.org/pdf/1708.00781.pdf.
Thanks – amended!